# RWKV-LM
We propose the RWKV language model, with alternating time-mix and channel-mix layers:
 * The R, K, V are generated by linear transforms of input, and W is parameter. The idea of RWKV is to decompose attention into R(target) * W(src, target) * K(src). So we can call R "receptance", and sigmoid means it's in 0~1 range.
* The Time-mix is similar to AFT (https://arxiv.org/abs/2105.14103). There are two differences.
(1) We changed the normalization (denominator). For masked language models, we define:
* The R, K, V are generated by linear transforms of input, and W is parameter. The idea of RWKV is to decompose attention into R(target) * W(src, target) * K(src). So we can call R "receptance", and sigmoid means it's in 0~1 range.
* The Time-mix is similar to AFT (https://arxiv.org/abs/2105.14103). There are two differences.
(1) We changed the normalization (denominator). For masked language models, we define:
 (2) We decompose W_{t,u,c} and introduce multi-head W (here h is the corresponding head of c):
(2) We decompose W_{t,u,c} and introduce multi-head W (here h is the corresponding head of c):
 Moreover we multiply the final output of Time-mix layer by γ(t). The reason for the α β γ factors, is because the context size is smaller when t is small, and this can be compensated using the α β γ factors.
* The Channel-mix is similar to GeGLU (https://arxiv.org/abs/2002.05202) with an extra R factor.
* Finally, we add extra time-mixing as in (https://github.com/BlinkDL/minGPT-tuned). You can try reducing the amt of time-mixing in upper layers of deep models.
***
We also propose a new sampling method (as in src/utils.py):
(1) Find the max probability p_max after softmax.
(2) Remove all entries whose probability is lower than 0.02 * pow(p_max, 2)
(3) Feel free to tune the 0.02 and 2 factor.
***
Character-level loss on simplebooks-92 dataset https://dldata-public.s3.us-east-2.amazonaws.com/simplebooks.zip
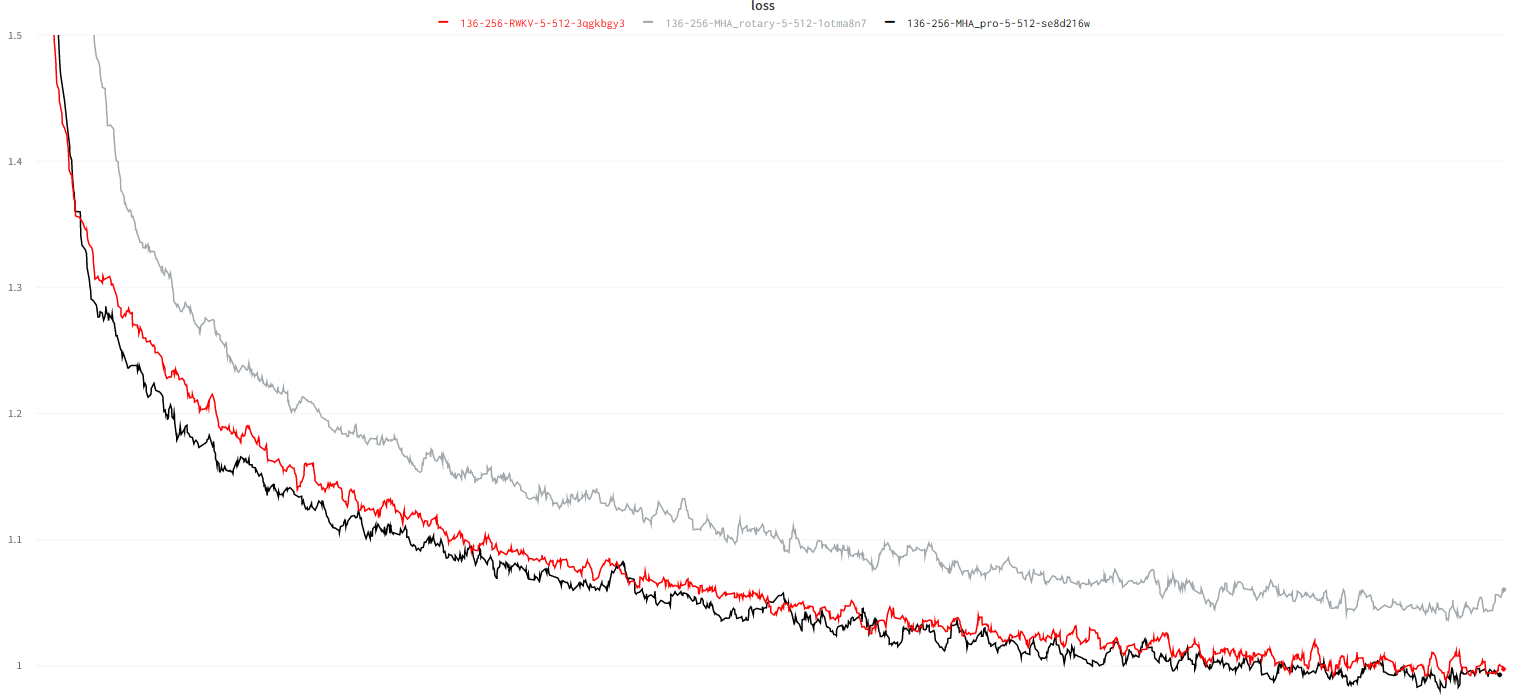
Gray: usual MHA+Rotary+GeGLU - performance not as good.
Red: RWKV ("linear" attention) - VRAM friendly - quite faster when ctx window is long - good performance.
Black: MHA_pro (MHA with various tweaks & RWKV-type-FFN) - slow - needs more VRAM - good performance.
parameters count: 17.2 vs 18.5 vs 18.5.
Moreover we multiply the final output of Time-mix layer by γ(t). The reason for the α β γ factors, is because the context size is smaller when t is small, and this can be compensated using the α β γ factors.
* The Channel-mix is similar to GeGLU (https://arxiv.org/abs/2002.05202) with an extra R factor.
* Finally, we add extra time-mixing as in (https://github.com/BlinkDL/minGPT-tuned). You can try reducing the amt of time-mixing in upper layers of deep models.
***
We also propose a new sampling method (as in src/utils.py):
(1) Find the max probability p_max after softmax.
(2) Remove all entries whose probability is lower than 0.02 * pow(p_max, 2)
(3) Feel free to tune the 0.02 and 2 factor.
***
Character-level loss on simplebooks-92 dataset https://dldata-public.s3.us-east-2.amazonaws.com/simplebooks.zip

Gray: usual MHA+Rotary+GeGLU - performance not as good.
Red: RWKV ("linear" attention) - VRAM friendly - quite faster when ctx window is long - good performance.
Black: MHA_pro (MHA with various tweaks & RWKV-type-FFN) - slow - needs more VRAM - good performance.
parameters count: 17.2 vs 18.5 vs 18.5.