|
|
5 years ago | |
|---|---|---|
| src | 5 years ago | |
| .gitignore | 5 years ago | |
| LICENSE | 5 years ago | |
| README.md | 5 years ago | |
| RWKV-vs-MHA.png | 5 years ago | |
| train.py | 5 years ago | |
{kind=link}
README.md
RWKV-LM
We propose the RWKV language model, with alternating time-mix and channel-mix layers:
-
Here R, K, V is generated by linear transforms of input.
-
The Time-mix is similar to AFT (https://arxiv.org/abs/2105.14103). There are two differences.
(1) We changed the softmax normalization. For masked language models, we define:
(2) We decompose W_{t,u,c} and introduce multi-head W (here h is the corresponding head of c):
Moreover we multiply the final output of Time-mix layer by γ(t). The reason for the α β γ factors, is because the context size is smaller when t is small, and this can be compensated using the α β γ factors.
-
The Channel-mix is similar to GeGLU (https://arxiv.org/abs/2002.05202) with an extra R factor.
-
Finally, we add extra time-mixing as in (https://github.com/BlinkDL/minGPT-tuned)
Training loss, RWKV vs MHA+Rotary+GeGLU:
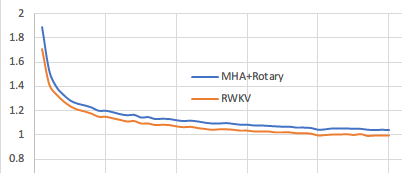
(this is character-level loss with simplebooks-92 dataset https://dldata-public.s3.us-east-2.amazonaws.com/simplebooks.zip)