|
|
5 years ago | |
|---|---|---|
| src | 5 years ago | |
| .gitignore | 5 years ago | |
| CITATION.cff | 5 years ago | |
| LICENSE | 5 years ago | |
| README.md | 5 years ago | |
| RWKV-time-w.png | 5 years ago | |
| RWKV-vs-MHA.png | 5 years ago | |
| train.py | 5 years ago | |
{kind=link}
{kind=link}
README.md
The RWKV Language Model
We propose the RWKV language model, with alternating time-mix and channel-mix layers:
-
The R, K, V are generated by linear transforms of input, and W is parameter. The idea of RWKV is to decompose attention into R(target) * W(src, target) * K(src). So we can call R "receptance", and sigmoid means it's in 0~1 range.
-
The Time-mix is similar to AFT (https://arxiv.org/abs/2105.14103). There are two differences.
(1) We changed the normalization (denominator). For masked language models, we define:
Initialize K and R matrices (and the output projection matrix) to ZERO for fast & stable convergence.
(2) We decompose W_{t,u,c} and introduce multi-head W (here h is the corresponding head of c):
Moreover we multiply the final output of Time-mix layer by γ(t). The reason for the α β γ factors, is because the context size is smaller when t is small, and this can be compensated using the α β γ factors.
-
The Channel-mix is similar to GeGLU (https://arxiv.org/abs/2002.05202) with an extra R factor. Initialize R and W matrices to ZERO for fast & stable convergence.
-
Finally, we add extra token-shift (time-shift mixing) as in (https://github.com/BlinkDL/minGPT-tuned).
Token-shift (time-shift mixing)
The token-shift means explicitly using both (half channel of this token) & (half channel of prev token) to generate all vectors.
I found dividing channels by 2 and shift-1 works the best for Chinese LM. You may want to use more shift for English char-level LM. I checked the weights and found you may want to use less mixing in higher layers.
My theory on the effectiveness of token-shift:
When we train a GPT, the hidden representation of a token has to accomplish two different objects:
-
Predict the next token. Sometimes this is easy (obvious next token).
-
Collect all previous context info, so later tokens can use it. This is always hard.
The shifted channels can focus on (2), so we have good propagation of info. It's like some kind of residual connection, or a small RNN inside the transformer.
You can use token-shift in usual QKV self-attention too. I looked at the weights, and found V really likes the shifted channels, less so for Q. Makes sense if you think about it.
p.s. There is a MHA_pro model in this repo with strong performance. Give it a try :)
The top-a Sampling method
We also propose a new sampling method called top-a (as in src/utils.py):
(1) Find the max probability p_max after softmax.
(2) Remove all entries whose probability is lower than 0.02 * pow(p_max, 2). So it's adaptive, hence "top-a".
(3) Feel free to tune the 0.02 and 2 factor.
Performance
Character-level loss on simplebooks-92 dataset https://dldata-public.s3.us-east-2.amazonaws.com/simplebooks.zip
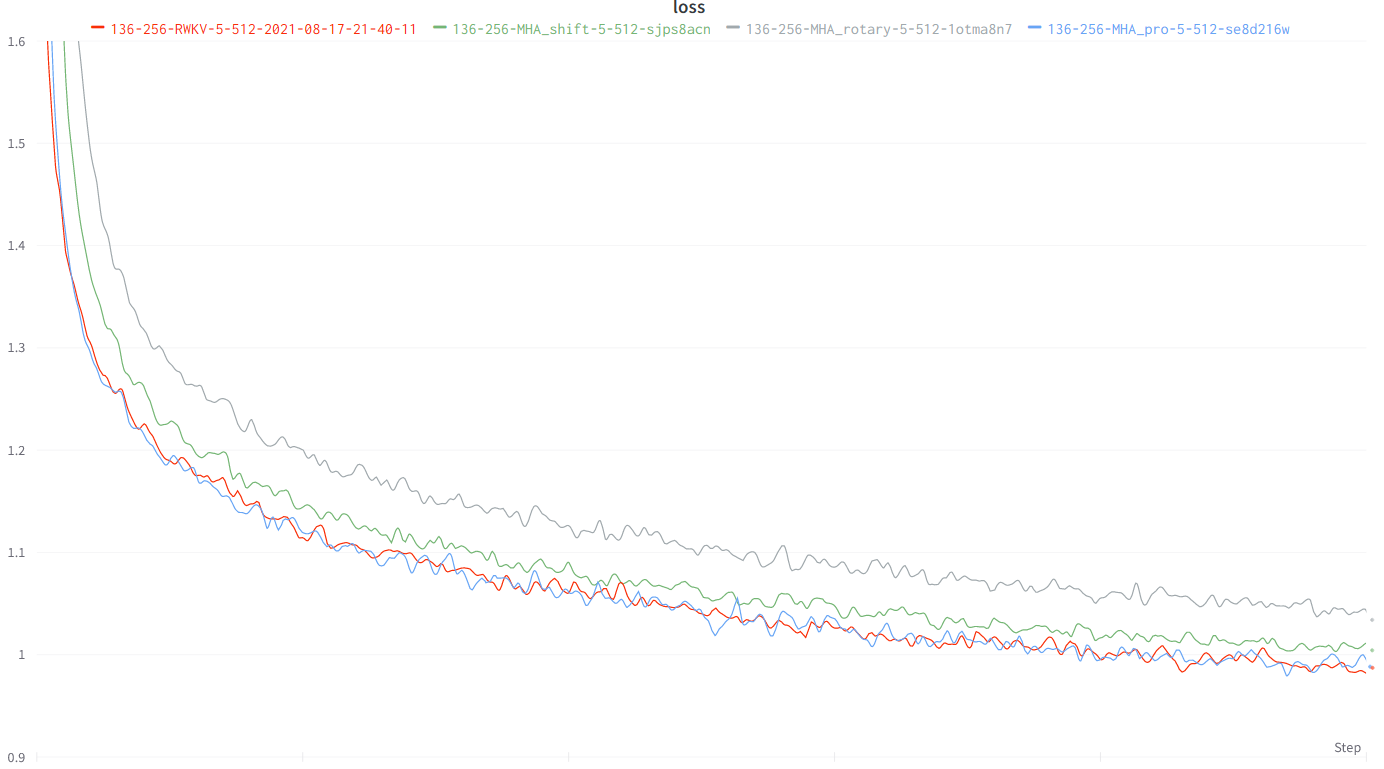
Gray: usual MHA+Rotary+GeGLU - performance not as good. 17.2M params.
Red: RWKV ("linear" attention) - VRAM friendly - quite faster when ctx window is long - good performance. 16.6M params.
Green: MHA+Rotary+GeGLU+Token_shift. 17.2M params.
Blue: MHA_pro (MHA with various tweaks & RWKV-type-FFN) - slow - needs more VRAM - good performance. 16.6M params.
@software{peng_bo_2021_5196578,
author = {PENG Bo},
title = {BlinkDL/RWKV-LM: 0.01},
month = aug,
year = 2021,
publisher = {Zenodo},
version = {0.01},
doi = {10.5281/zenodo.5196577},
url = {https://doi.org/10.5281/zenodo.5196577}
}
Initialization
We use careful initialization for RWKV to get fast convergence - orthogonal matrices with proper scaling, and special time_w curves. Check model.py for details.
Some learned time_w examples: